As neural networks are being popular, you might want to be interested in applying them into your videos in order to create some unique scenes that make viewers question the term called originality. So this article will guide you to think what you can further do with neural networks (technologies are shown from easiest to hardest).
1. RunwayML
Overview
RunwayML is a service that lets you do various image/video processings fast and easy. It does not have advanced controls, but it is very easy to work with this.
Requirements & Installation
All you need is to register to the service and it gives you some credits as a sign up bonus, so you can play with the software.
Experimentation
#1: Gen-1
Allows you to copy one style of the video to another video.
#2: Gen-2
Allows you to create a video from textual input. The result is quite unstable.
#3: Remove Background (Automasking)
Allows you to remove background from shots. Works quite well for garbage matting, Does not work well with dark, unclean shots. Requires Google Chrome.
Also, you can do inpainting, frame interpolation, image expanding, etc. for different types of experiments.
2. AnimeGAN
Transforms video into anime style. You can select different types of styles: Hayao Style, Shinkai style, Disney Style, etc.
All you need is download the repository (https://github.com/TachibanaYoshino/AnimeGANv3, click Code->Download Zip), go to AnimeGANv3, execute AnimeGANv3.exe and use it to transform video into anime.
3. Stable Diffusion
Requirements
First of all, let's start with compatibility. As you know, artificial intelligence consumes a lot of power and needs high end technology (specifically high end GPUs), which unfortunately not everyone can afford. So, in order to offer compatibility for everyone, we will start with Google Colab.
Google Colab - the area containing high end GPUs which you can run code for free. The only drawback is that the server might be unstable and shuts down after some time.
In order to use this technology, all you need to have an account within Google services.
Secondly, a bit about Stable Diffusion. It is open source image creation library with using textual prompts. The result is not often good as another alternative - Midjourney, but hey, it is completely free. On top of that it is possible to tweak the various parts of an image making your prompts way more consistent. It is possible to install it into your computer, but we will proceed to using this technology with Google Colab.
Stable diffusion starts with noise and begins generating an image using text prompt conditioning (the information extracted from a language model that tells the U-Net how to modify the image). At each step, practically the model adds detail and the noise is removed. During the various steps in latent space what was once noise becomes more and more like an image. After that, the decoder transforms what was noise into an image in the pixel space. [source]
Thirdly, there is a library called Gradio. It allows you to visualize console applications into web application and share it.
Now as we know the a bit about the theoretical part, we will move into practical part.
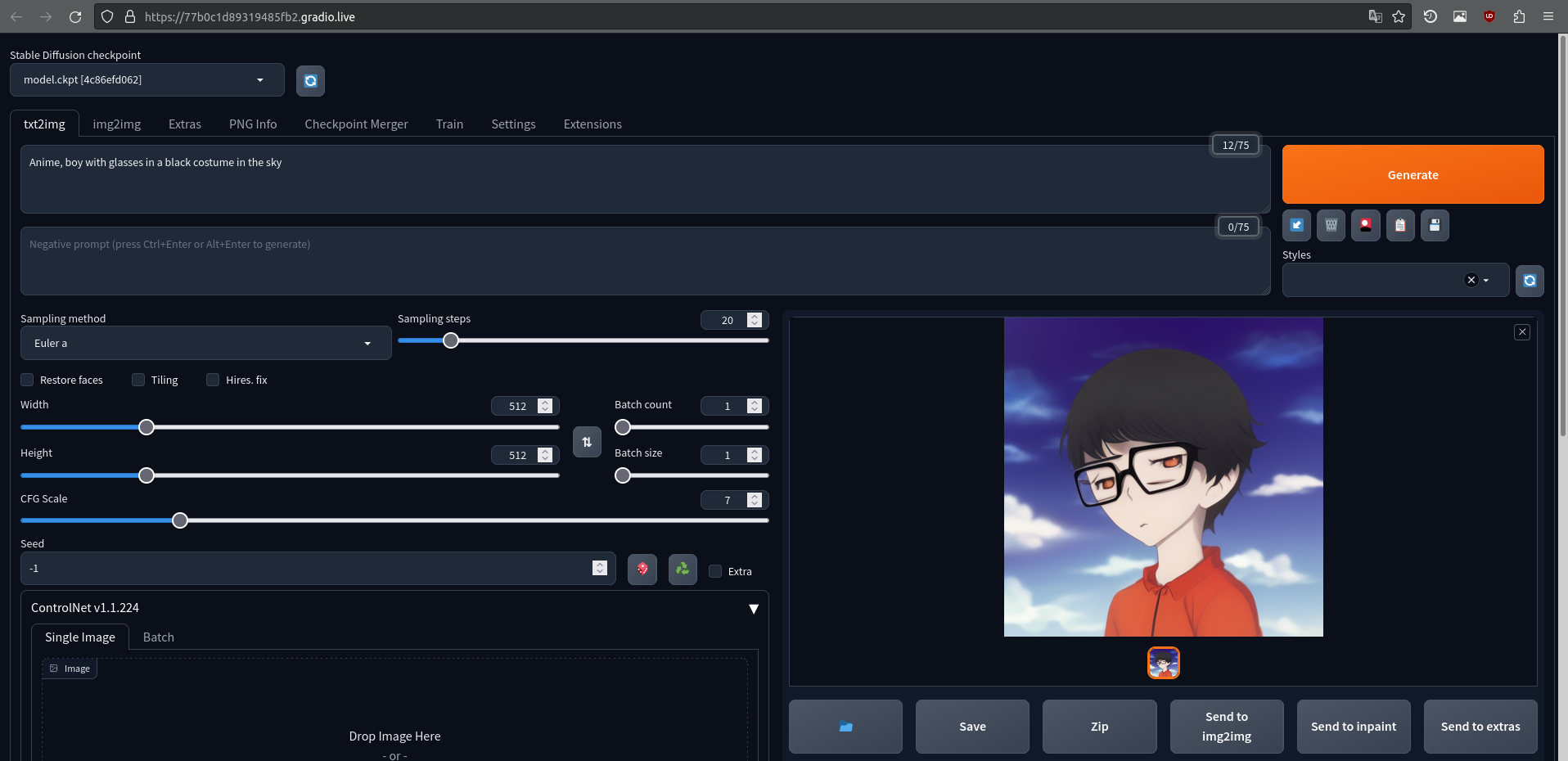
Basic Stable Diffusion allows you to create image from textual prompts. For example, if you write "Anime, boy with glasses in a black costume in the sky", it will try to create image suitable for this description.
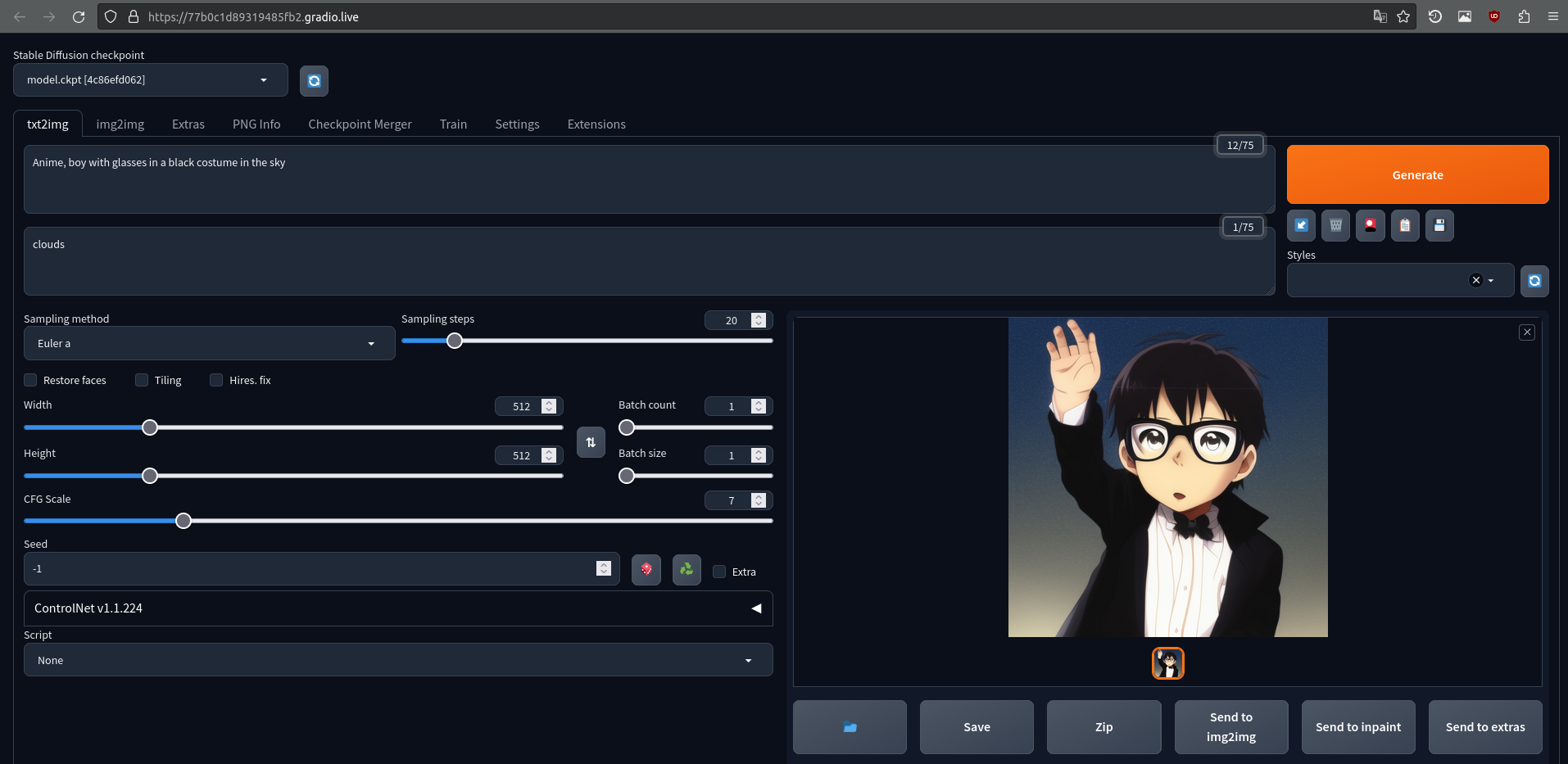
Negative prompt is the textual prompt that you do not want to see in the image. For example, if you write "Anime, boy with glasses in a black costume in the sky" in the prompt field, and if you write 'clouds' in the negative prompt field, then you won't see clouds in the generated image.
With inpainting, you can change any part of the image to your preference. Just brush the needed part to change ( or to keep), And describe the alterations that needs to be here.
Sketching
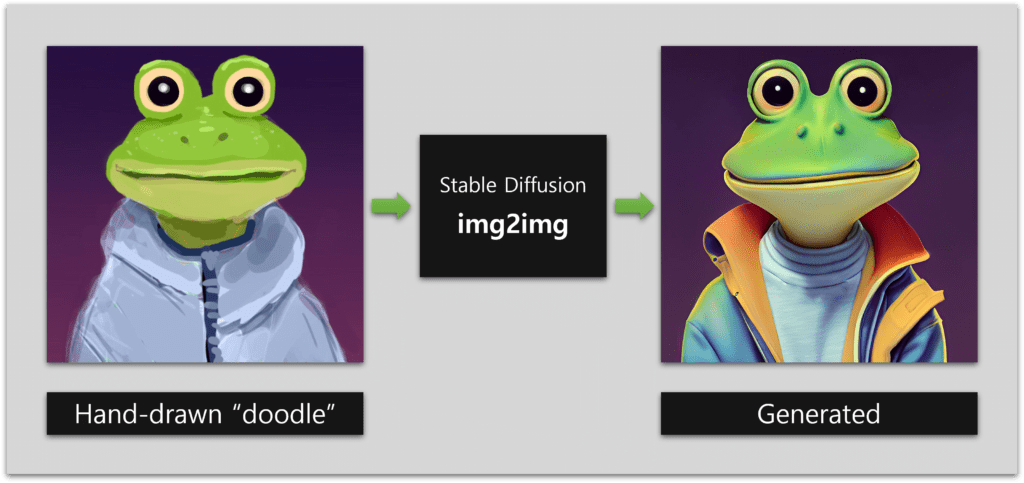
With sketching, you can draw rough idea of what should look like the image and ControlNet converts into actual image.
Resizing
You can denoise & resize do other image processing from Extras Tab.
You can also play with ControlNet which allows far more control for the output, but you will need to install it locally or buy Google Colab paid subscription.
There is a library called Audiocraft that generates music based on MusicGen. You can try describing music to your tastes and get the output for your prompt.
Поскольку нейронные сети становятся популярными, вы можете захотеть использовать их в своих видео, чтобы создавать уникальные сцены, которые заставят зрителей усомниться в термине "оригинальность". Итак, эта статья поможет вам подумать, что вы можете сделать с нейронными сетями (технологии показаны от самых простых к самым сложным).
1. RunwayML
Описание
RunwayML — это сервис, который позволяет быстро и легко выполнять различные обработки изображений/видео. У него нет расширенного управления, но с этим очень легко работать.
Требования и требования Установка
Все, что вам нужно, это зарегистрироваться в сервисе, и он даст вам несколько кредитов в качестве бонуса за регистрацию, чтобы вы могли играть с программным обеспечением.
Эксперимент
#1: Gen-1
Позволяет копировать один стиль видео в другое видео.
#2: Gen-2
Позволяет создавать видео из текстового ввода. Результат весьма нестабилен.
#3. Удаление фона (автомаскирование)
Позволяет удалить фон со снимков. Достаточно хорошо работает для матирования мусора, плохо работает с темными, грязными снимками. Требуется Google Chrome.
Кроме того, вы можете выполнять отрисовку, интерполяцию кадров, расширение изображения и т. д. для различных типов экспериментов.
2. AnimeGAN
Превращает видео в аниме-стиль. Вы можете выбрать различные типы стилей: стиль Хаяо, стиль Синкай, стиль Диснея и т. д.
Все, что вам нужно, это загрузить репозиторий (https://github.com/TachibanaYoshino/AnimeGANv3, нажать «Код» -> «Загрузить Zip»), перейти к AnimeGANv3, запустить AnimeGANv3.exe и использовать его для преобразования видео в аниме.
3. Stable Diffusion
Требования
Прежде всего, начнем с совместимости. Как вы знаете, искусственный интеллект потребляет много энергии и требует высоких технологий (в частности, высокопроизводительных графических процессоров), которые, к сожалению, не каждый может себе позволить. Итак, чтобы обеспечить совместимость для всех, мы начнем с Google Colab.
Google Colab — область, содержащая высококачественные графические процессоры, на которых вы можете бесплатно запускать код. Единственным недостатком является то, что сервер может работать нестабильно и отключаться через некоторое время.
Чтобы использовать эту технологию, вам достаточно иметь учетную запись в службах Google.
Во-вторых, немного о Stable Diffusion. Это библиотека для создания изображений с открытым исходным кодом с использованием текстовых подсказок. Результат не так хорош, как другая альтернатива — Midjourney, но она совершенно бесплатна. Кроме того, можно настроить различные части изображения, чтобы сделать ваши подсказки более последовательными. Ее можно установить на свой компьютер, но мы перейдем к использованию этой технологии с Google Colab.
Стабильная диффузия начинается с шума и начинает генерировать изображение с использованием текстовых подсказок (информация, извлеченная из языковой модели, которая сообщает U-Net, как изменить изображение). Практически на каждом этапе модель добавляет детали, а шум удаляется. При различных шагах в скрытом пространстве то, что когда-то было шумом, становится все более и более похожим на изображение. После этого декодер преобразует то, что было шумом, в изображение в пространстве пикселей. [источник]
В-третьих, есть библиотека под названием Gradio. Он позволяет визуализировать консольные приложения в веб-приложения и можно поделиться ими.
Теперь, когда мы немного разобрались с теоретической частью, мы перейдем к практической части.
Базовый Stable Diffusion позволяет создавать изображения из текстовых подсказок. Например, если вы напишете "Аниме, мальчик в очках в черном костюме в небе", он попытается создать изображение, подходящее для этого описания.
Отрицательная подсказка — это текстовая подсказка, которую вы не хотите видеть на изображении. Например, если написать «Аниме, мальчик в очках в черном костюме в небе»; в поле подсказки, а если вы напишете «облака» в поле отрицательной подсказки, то вы не увидите облаков на сгенерированном изображении.
С помощью inpaint вы можете изменить любую часть изображения по своему усмотрению. Просто почистите ту часть, которую нужно изменить (или оставить), и опишите изменения, которые должны быть здесь.
Эскиз
С помощью набросков вы можете нарисовать примерное представление о том, как должно выглядеть изображение, и ControlNet преобразует его в фактическое изображение.
Изменение размера
Вы можете шумоподавить & изменить размер, выполнить другую обработку изображения на вкладке «Дополнительно».
Вы также можете поиграть с ControlNet, который дает гораздо больше контроля над выводом, но вам нужно будет установить его локально или купить платную подписку Google Colab.
Существует библиотека Audiocraft, которая генерирует музыку на основе MusicGen. Вы можете попробовать описать музыку на свой вкус и получить результат который соответствует вашему описанию.